Introduction
I have been procastinating on this for a while, and did not post since march: shame on me!
Since I just rebuilt my production cluster with proxmox/talos, I took the opportunity to run some storage benchmarks to compare rook-ceph’s performance between k8s running on proxmox and k8s running on raspberry pi (version 4 wit 8GB).
The setups are comparable:
- I use talos to run kubernetes (different version though) on both arm64 and amd64 architectures
- I run rook-ceph in cluster: each cluster has three nodes with local storage (second partition) that are allocated to rook-ceph. More on the setup can be found [here](https://rook.io/docs/rook/v1.12/Getting-Started/quickstart/#create-a-ceph-cluster
- the rook-ceph config is the same: I use replicated storage on three nodes. On the raspi these are USB attached NVMe drives (I know!) and on proxmox these are secondary volumes on SSD.
Tooling
I decided to get a stab at kubestr by Kasten for benchmarking. Unfortunately the project does not provide any docker image for arm64 so I had to build my own.
Method
I did three runs using kubestr v1.26.0:
- on amd64:
kubestr fio -s rook-ceph-block - on arm64:
kubestr fio -s rook-ceph-block --image asksven/kubestr:arm64-1(the image I linked above)
and wrote down the average IOPS for each run. The figures are the average of the averages.
I also ran some test with different pvc sizes, e.g. 20Gi instead of the default 100Gi, but did not notice any difference.
Results
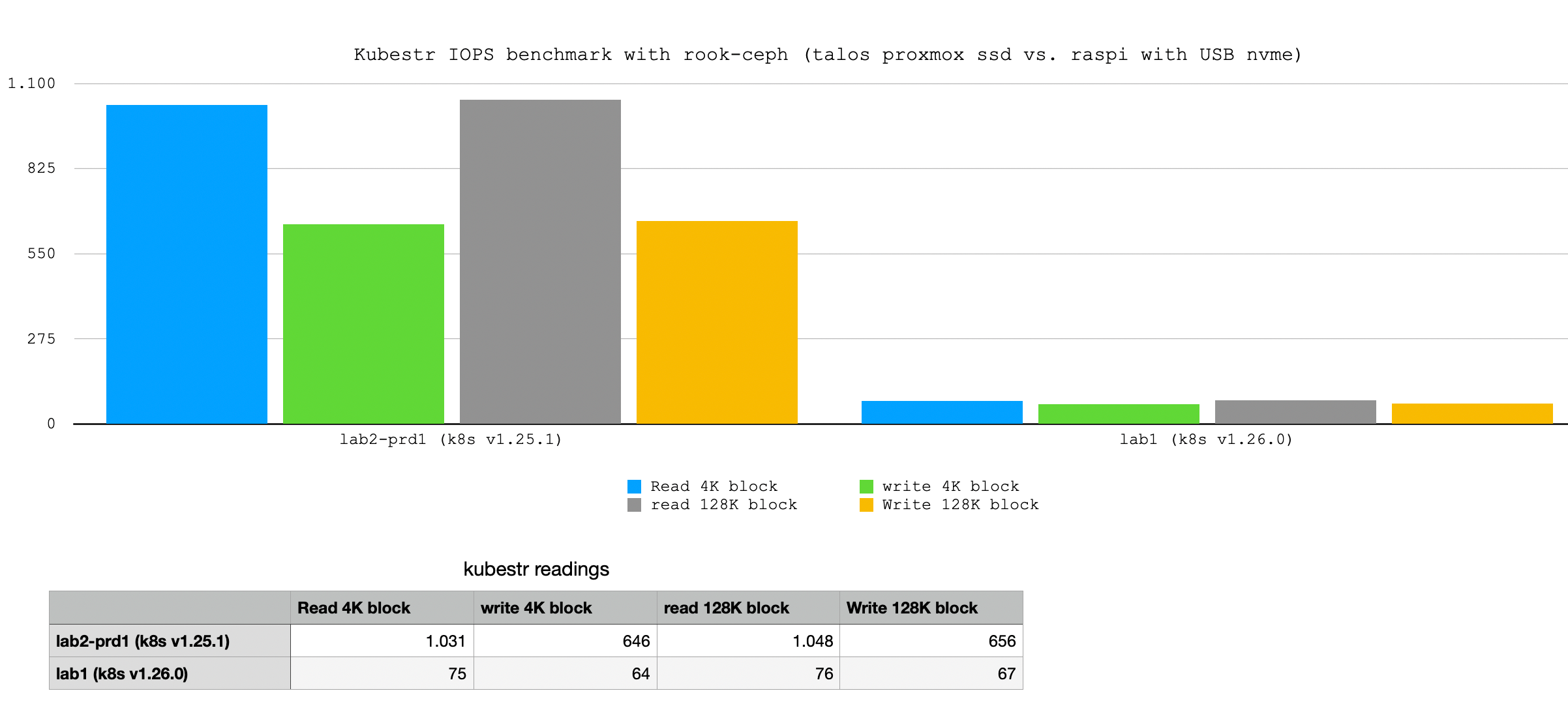
Conclusion
I can not say if my production environment is fast or not (update to come), but it is clear that native (even if virtualized through proxmox) storage is far superior compared to USB attached to Raspberry PIs by a factor > 10x in reads and approcximately 10x in writes. The bandwith results show that even if the benchmark does not reach the USB 3.0 spec (of practically 450 MB/s), it is still 77MB/s. I will probably do some more benchmarks without storage replication to see if I get nearer to the native throughput. I will also update this post after running benchmarks against AKS since I have a cluster available to do that.